
空结构体占用空间么
在 Go 语言中,我们可以使用 unsafe.Sizeof 计算出一个数据类型实例需要占用的字节数。
fmt.Println(unsafe.Sizeof(struct{}{}))
运行上面的例子将会输出:
$ go run main.go
0
也就是说,空结构体 struct{} 实例不占据任何的内存空间。
空结构体的作用
因为空结构体不占据内存空间,因此被广泛作为各种场景下的占位符使用。一是节省资源。二是空结构体本身就具备很强的语义,即这里不需要任何值,仅作为占位符。
实现集合(Set)
Go 语言标准库没有提供 Set 的实现,通常使用 map 来代替。事实上,对于集合来说,只需要 map 的键,而不需要值。即使是将值设置为 bool 类型,也会多占据 1 个字节,那假设 map 中有一百万条数据,就会浪费 1MB 的空间。
因此呢,将 map 作为集合(Set)使用时,可以将值类型定义为空结构体,仅作为占位符使用即可。
type Set map[string]struct{}
func (s Set) Has(key string) bool {
_, ok := s[key]
return ok
}
func (s Set) Add(key string) {
s[key] = struct{}{}
}
func (s Set) Delete(key string) {
delete(s, key)
}
func main() {
s := make(Set)
s.Add("Tom")
s.Add("Sam")
fmt.Println(s.Has("Tom"))
fmt.Println(s.Has("Jack"))
}
不发送数据的信道(channel)
有时候使用channel不需要发送任何的数据,只用来通知子协程(goroutine)执行任务,或只用来控制协程并发度。这种情况下,使用空结构体作为占位符就非常合适了。
func worker(ch chan struct{}) {
<-ch
fmt.Println("do something")
close(ch)
}
func main() {
ch := make(chan struct{})
go worker(ch)
ch <- struct{}{}
}
仅包含方法的结构体
type Door struct{}
func (d Door) Open() {
fmt.Println("Open the door")
}
func (d Door) Close() {
fmt.Println("Close the door")
}
在部分场景下,结构体只包含方法,不包含任何的字段。例如上面例子中的 Door,在这种情况下,Door 事实上可以用任何的数据结构替代。例如:
type Door int
type Door bool
无论是 int 还是 bool 都会浪费额外的内存,因此呢,这种情况下,声明为空结构体是最合适的。
内存对齐
为什么需要内存对齐
CPU 访问内存时,并不是逐个字节访问,而是以字长(word size)为单位访问。比如32位的CPU ,字长为4字节,那么CPU访问内存的单位也是 4 字节。
这么设计的目的,是减少CPU访问内存的次数,加大CPU访问内存的吞吐量。比如同样读取8个字节的数据,一次读取4个字节那么只需要读取2次。
CPU 始终以字长访问内存,如果不进行内存对齐,很可能增加 CPU 访问内存的次数,例如:
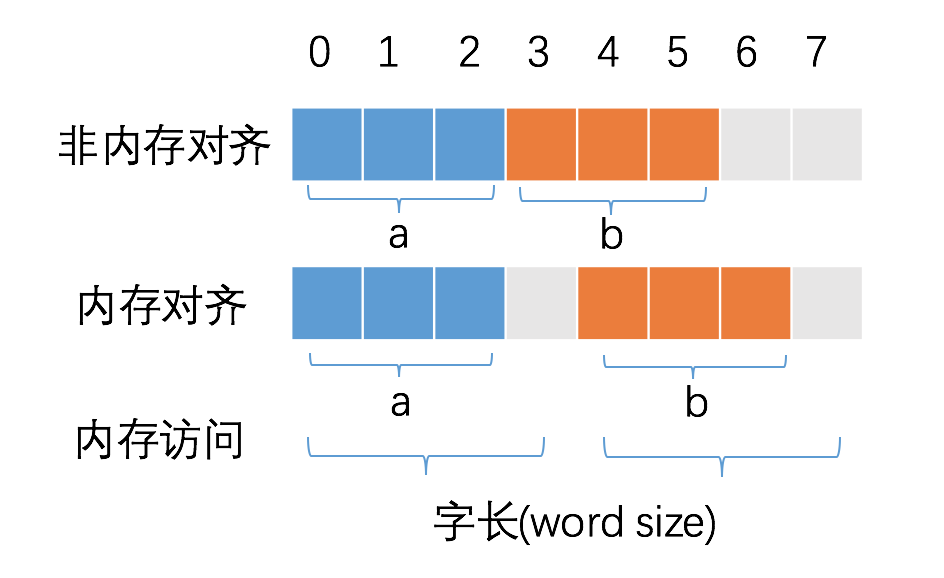
变量a、b各占据3字节的空间,内存对齐后,a、b占据4字节空间,CPU读取b变量的值只需要进行一次内存访问。如果不进行内存对齐,CPU读取b变量的值需要进行2次内存访问。第一次访问得到b变量的第1个字节,第二次访问得到b变量的后两个字节。
从这个例子中也可以看到,内存对齐对实现变量的原子性操作也是有好处的,每次内存访问是原子的,如果变量的大小不超过字长,那么内存对齐后,对该变量的访问就是原子的,这个特性在并发场景下至关重要。
简言之:合理的内存对齐可以提高内存读写的性能,并且便于实现变量操作的原子性。
如何计算结构体占用的空间
package main
import (
"fmt"
"unsafe"
)
type Args struct {
num1 int
num2 int
}
type Flag struct {
num1 int16
num2 int32
}
func main() {
fmt.Println(unsafe.Sizeof(Args{}))
fmt.Println(unsafe.Sizeof(Flag{}))
}
运行上面的例子将会输出:
$ go run main.go
16
8
- Args由2个int类型的字段构成,在64位机器上,一个int占8字节,因此存储一个Args实例需要16字节。
- Flag由一个int32和一个int16的字段构成,成员变量占据的字节数为4+2=6,但是unsafe.Sizeof返回的结果为8字节,多出来的2字节是内存对齐的结果。
因此,一个结构体实例所占据的空间等于各字段占据空间之和,再加上内存对齐的空间大小。
unsafe.Alignof
在上面的例子中,Flag{}两个字段占据了6个字节,但是最终对齐后的结果是8字节。Go语言中内存对齐需要遵循什么规律呢?
unsafe标准库提供了Alignof方法,可以返回一个类型的对齐值,也可以叫做对齐系数或者对齐倍数。例如:
unsafe.Alignof(Args{}) // 8
unsafe.Alignof(Flag{}) // 4
- Args{}的对齐倍数是8,Args{}两个字段占据16字节,是8的倍数,无需占据额外的空间对齐。
- Flag{}的对齐倍数是4,因此Flag{}占据的空间必须是4的倍数,因此,6内存对齐后是8字节。
对齐保证(align guarantee)
Go官方文档Size and alignment guarantees - golang spec描述了unsafe.Alignof的规则。
- For a variable x of any type: unsafe.Alignof(x) is at least 1.(对于任意类型的变量x ,unsafe.Alignof(x)至少为1。)
- For a variable x of struct type: unsafe.Alignof(x) is the largest of all the values unsafe.Alignof(x.f) for each field f of x, but at least 1.(对于struct结构体类型的变量x,计算x每一个字段f的unsafe.Alignof(x.f),unsafe.Alignof(x)等于其中的最大值。)
- For a variable x of array type: unsafe.Alignof(x) is the same as the alignment of a variable of the array’s element type.(对于array数组类型的变量x,unsafe.Alignof(x)等于构成数组的元素类型的对齐倍数。)
A struct or array type has size zero if it contains no fields (or elements, respectively) that have a size greater than zero. Two distinct zero-size variables may have the same address in memory.
没有任何字段的空struct{}和没有任何元素的array占据的内存空间大小为0,不同的大小为0的变量可能指向同一块地址。
struct内存对齐的技巧
合理布局减少内存占用
假设一个struct包含三个字段,a int8、b int16、c int64,顺序会对 struct的大小产生影响吗?我们来做一个实验:
type demo1 struct {
a int8
b int16
c int32
}
type demo2 struct {
a int8
c int32
b int16
}
func main() {
fmt.Println(unsafe.Sizeof(demo1{})) // 8
fmt.Println(unsafe.Sizeof(demo2{})) // 12
}
答案是会产生影响。每个字段按照自身的对齐倍数来确定在内存中的偏移量,字段排列顺序不同,上一个字段因偏移而浪费的大小也不同。
接下来逐个分析,首先是demo1:
- a是第一个字段,默认是已经对齐的,从第0个位置开始占据1字节。
- b是第二个字段,对齐倍数为2,因此,必须空出1个字节,偏移量才是2 的倍数,从第2个位置开始占据2字节。
- c是第三个字段,对齐倍数为4,此时,内存已经是对齐的,从第4个位置开始占据4字节即可。
因此 demo1 的内存占用为 8 字节。
接下来是demo2:
- a是第一个字段,默认是已经对齐的,从第0个位置开始占据1字节。
- c是第二个字段,对齐倍数为4,因此,必须空出3个字节,偏移量才是4的倍数,从第4个位置开始占据4字节。
- b是第三个字段,对齐倍数为2,从第8个位置开始占据2字节。
- demo2的对齐倍数由c的对齐倍数决定,也是4,因此,demo2的内存占用为12字节。
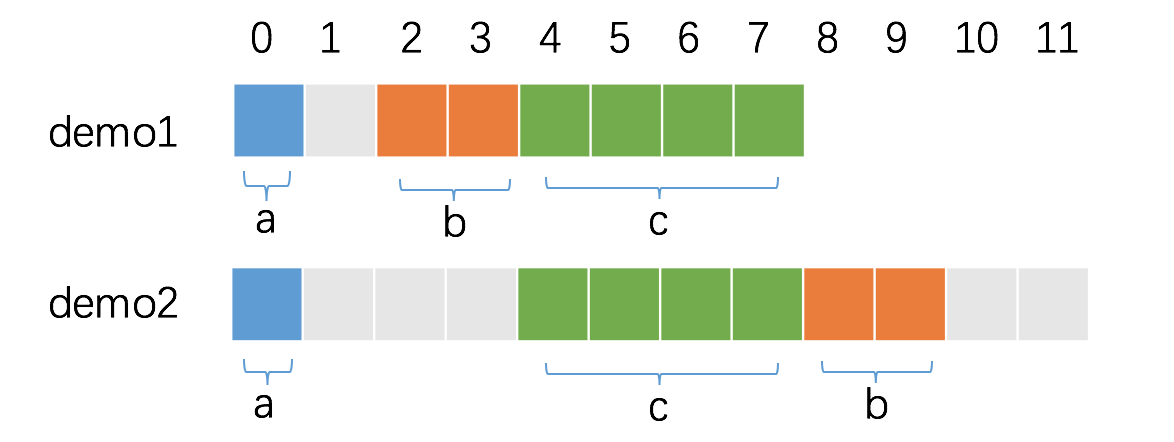
因此,在对内存特别敏感的结构体的设计上,我们可以通过调整字段的顺序,减少内存的占用。
空struct{}的对齐
空struct{}大小为0,作为其他struct的字段时,一般不需要内存对齐。但是有一种情况除外:即当struct{}作为结构体最后一个字段时,需要内存对齐。因为如果有指针指向该字段, 返回的地址将在结构体之外,如果此指针一直存活不释放对应的内存,就会有内存泄露的问题(该内存不因结构体释放而释放)。
因此,当struct{}作为其他struct最后一个字段时,需要填充额外的内存保证安全。我们做个试验,验证下这种情况。
type demo3 struct {
c int32
a struct{}
}
type demo4 struct {
a struct{}
c int32
}
func main() {
fmt.Println(unsafe.Sizeof(demo3{})) // 8
fmt.Println(unsafe.Sizeof(demo4{})) // 4
}
可以看到,demo4{}的大小为4字节,与字段c占据空间一致,而demo3{}的大小为8字节,即额外填充了4字节的空间。
原理解密:特殊变量zerobase
空结构体是没有内存大小的结构体。这句话是没有错的,但是更准确的来说,其实是有一个特殊起点的,那就是zerobase变量,这是一个uintptr全局变量,占用8个字节。当在任何地方定义无数个struct {}类型的变量,编译器都只是把这个zerobase变量的地址给出去。换句话说,在golang里面,涉及到所有内存size为0的内存分配,那么就是用的同一个地址&zerobase。
举个例子:
package main
import "fmt"
type emptyStruct struct {}
func main() {
a := struct{}{}
b := struct{}{}
c := emptyStruct{}
fmt.Printf("%p\n", &a)
fmt.Printf("%p\n", &b)
fmt.Printf("%p\n", &c)
fmt.Printf("%p\n", &d)
}
dlv 调试分析一下:
(dlv) p &a
(*struct {})(0x57bb60)
(dlv) p &b
(*struct {})(0x57bb60)
(dlv) p &c
(*main.emptyStruct)(0x57bb60)
(dlv) p &runtime.zerobase
(*uintptr)(0x57bb60)
struct{}作为receiver
receiver是golang里struct具有的基础特点。空结构体本质上作为结构体也是一样的,可以作为receiver来定义方法。
type emptyStruct struct{}
func (e *emptyStruct) FuncB(n, m int) {
}
func (e emptyStruct) FuncA(n, m int) {
}
func main() {
a := emptyStruct{}
n := 1
m := 2
a.FuncA(n, m)
a.FuncB(n, m)
}
receiver这种写法是golang支撑面向对象的基础,本质上的实现也是非常简单,常规情况(普通的结构体)可以翻译成:
func FuncA (e *emptyStruct, n, m int) {
}
func FuncB (e emptyStruct, n, m int) {
}
**编译器只是把对象的值或地址作为第一个参数传给这个函数而已,就这么简单。**但是在这里要提一点,空结构体稍微有一点点不一样,空结构体应该翻译成:
func FuncA (e *emptyStruct, n, m int) {
}
func FuncB (n, m int) {
}
极其简单的代码,对应的汇编实际代码FuncA,FuncB就这么简单,如下:
00000000004525b0 <main.(*emptyStruct).FuncB>:
4525b0: c3 retq
00000000004525c0 <main.emptyStruct.FuncA>:
4525c0: c3 retq
main 函数
00000000004525d0 <main.main>:
4525d0: 64 48 8b 0c 25 f8 ff mov %fs:0xfffffffffffffff8,%rcx
4525d9: 48 3b 61 10 cmp 0x10(%rcx),%rsp
4525dd: 76 63 jbe 452642 <main.main+0x72>
4525df: 48 83 ec 30 sub $0x30,%rsp
4525e3: 48 89 6c 24 28 mov %rbp,0x28(%rsp)
4525e8: 48 8d 6c 24 28 lea 0x28(%rsp),%rbp
4525ed: 48 c7 44 24 18 01 00 movq $0x1,0x18(%rsp)
4525f6: 48 c7 44 24 20 02 00 movq $0x2,0x20(%rsp)
4525ff: 48 8b 44 24 18 mov 0x18(%rsp),%rax
452604: 48 89 04 24 mov %rax,(%rsp) // n 变量值压栈(第一个参数)
452608: 48 c7 44 24 08 02 00 movq $0x2,0x8(%rsp) // m 变量值压栈(第二个参数)
452611: e8 aa ff ff ff callq 4525c0 <main.emptyStruct.FuncA>
452616: 48 8d 44 24 18 lea 0x18(%rsp),%rax
45261b: 48 89 04 24 mov %rax,(%rsp) // $rax 里面是 zerobase 的值,压栈(第一个参数);
45261f: 48 8b 44 24 18 mov 0x18(%rsp),%rax
452624: 48 89 44 24 08 mov %rax,0x8(%rsp) // n 变量值压栈(第二个参数)
452629: 48 8b 44 24 20 mov 0x20(%rsp),%rax
45262e: 48 89 44 24 10 mov %rax,0x10(%rsp) // m 变量值压栈(第三个参数)
452633: e8 78 ff ff ff callq 4525b0 <main.(*emptyStruct).FuncB>
452638: 48 8b 6c 24 28 mov 0x28(%rsp),%rbp
45263d: 48 83 c4 30 add $0x30,%rsp
452641: c3 retq
452642: e8 b9 7a ff ff callq 44a100 <runtime.morestack_noctxt>
452647: eb 87 jmp 4525d0 <main.main>
通过这段代码证实几个点:
- receiver其实就是一种语法糖,本质上就是作为第一个参数传入函数;
- receiver为值的场景,不需要传空结构体做第一个参数,因为空结构体没有值;
- receiver为一个指针的场景,对象地址作为第一个参数传入函数,函数调用的时候,编译器传入zerobase的值(编译期间就可以确认);
在二进制编译之后,一般e.FuncA的调用,第一个参数是直接压入&zerobase到栈里。
总结几个知识点:
- receiver本质上是非常简单的一个通用思路,就是把对象值或地址作为第一参数传入函数;
- 函数参数压栈方式从前往后(可以调试看下);
- 对象值作为receiver的时候,涉及到一次值拷贝;
- golang对于值做receiver的函数定义,会根据现实需要情况可能会生成了两个函数,一个值版本,一个指针版本(思考:什么是“需要情况”?就是有interface的场景 );
- 空结构体在编译期间就能识别出来的场景,编译器会对既定的事实,可以做特殊的代码生成;
可以这么说,编译期间,关于空结构体的参数基本都能确定,那么代码生成的时候,就可以生成对应的静态代码。
总结
- 空结构体也是结构体,只是size为0的类型而已;
- 所有的空结构体都有一个共同的地址:zerobase的地址;
- 空结构体可以作为 receiver ,receiver是空结构体作为值的时候,编译器其实直接忽略了第一个参数的传递,编译器在编译期间就能确认生成对应的代码;
- map和struct{}结合使用常常用来节省一点点内存,使用的场景一般用来判断 key 存在于map;
- chan和struct{}结合使用是一般用于信号同步的场景,用意并不是节省内存,而是我们真的并不关心chan元素的值;
原文地址
Go sync.Once | Go 语言高性能编程 | 极客兔兔
Go sync.Cond | Go 语言高性能编程 | 极客兔兔
Go 最细节篇 — 空结构体是什么? - 知乎
评论